
Raft 是一种分布式一致性算法,详细可见论文。主要作用是确保分布式系统的一致性问题。考虑主从模式的集群下,服务器挂掉或网络故障等情况发生时如何确保数据安全。在raft中,主节点称为leader,从节点称为follower。
下面我尝试以简洁流畅的语言描述raft算法的各个重要部分,某些地方会结合etcd/raft的源码说明。也可以结合raft.github.io这个网站的可视化工具来理解raft。
节点感知
leader和follower需要相互知道的对方存在,一般采用发心跳信息的方式。在raft中,一定是leader主动发心跳信息给follower,然后follower回应。
日志复制
日志复制也叫日志同步或日志分发,之所以叫日志复制是因为总是leader单方面将日志复制到followers上。raft尽可能保证leader和followers的日志进度相同,自动进行着日志的同步。每条日志有一个 log index 参数,严格递增,可以通过该参数判断该follower的同步进度。
可能新增日志的速度快于同步速度,为了确保顺序,会等旧日志同步完后再同步新日志。实现方法可能是,leader与各个follower之间维护一个队列,leader往队列投入日志,followers从队列获取日志。
日志提交
当一个日志同步给超过半数的节点后,leader就可以提交该日志。所谓提交在不同分布式场景中可能有不同的具体表现。比如,在分布式存储中,leader把数据复制到其他节点后并非就真的存储完成,可能只是把数据放到了内存上,只有超过半数节点拥有这一数据才肯定该数据是安全的,然后leader执行提交,通知其他所有节点可以把该数据存储到磁盘上。
follower故障
如果leader给follower发送的心跳信息长时间没有回应,可能有两种情况,一是follower挂了,二是网络分区(网络连接失败)。如果是前者,则该follower是不可用的,如果是后者,可能过段时间网络恢复后又会重新连上来。但leader无法分辨是哪种情况,一般措施是依旧把follower维持在集群中,并不断发送消息,尽管不能得到回复。只要集群中有过半节点正常运行,集群就是可用状态。
领导选举
leader并非万无一失,也可能会发生故障而挂掉。需要选举出新的leader,每选举出一个leader,每个节点上维护的任期号term加一。
当某个follower持续一定时间没有收到leader的心跳信息,该follower就会认为leader挂掉了,这时他会把自己变成candidate,先把自己的任期号term加一,给自己投一票后广播信息请求其他节点给它投票,信息会携带自己的term和log index。
其他节点收到信息后,先看看自己能不能投,可以重复投给一个节点,但投过一个后就不能投给另一个。可以投票的话就先比较term,如果对方term更大,就投票给它,如果term相同且对方log index更大,同样投票给它,否则拒绝投票 [src]。拒绝投票意味着对方没有资格参与选举,因为它的term或log index落后于人。拒绝投票消息会携带当前term,对方收到消息后就会把自己的term更新为消息中的term,然后把自己变回follower [src]。
如果请求投票期间,candidate收到leader的心跳,也会把自己变回follower [src]。
当一个candidate收到半数以上的投票,它就把自己变成leader并向其他节点发信息宣告这一消息。当然,也可能选举失败,比如若干个candidate拿到相同的票数,并且没有多余的票数,超时之后将自己的term加一并继续新一轮选举。
若是前一个leader在分发某一个日志过程中挂掉了怎么办?如果这条日志还没来得及分发到任何一个节点上,leader就已经挂掉,那么这条日志必然随着leader的挂掉而丢失。如果成功分发到一个节点及以上,那么新leader一定是具有该日志的,否则log index落后一定不会成为leader。新leader发现该日志还没提交,就会分发该日志。与之前任期重复分发了也没关系,同步时follower发现已存在log index,则以leader新发送的为准强制覆盖。
多数派
当一个candidate收到半数以上(多数派)的投票,它就把自己变成leader。但若是集群中过半节点都挂掉了,则意味着candidate永远无法获得过半数的投票,但它并不知道集群其他节点什么时候能恢复,选举超时后,它会继续发起选举。选举期间集群不可用,或者说不可对外服务,所以也就意味着集群中过半节点挂掉,则集群将不可用。
成员变更
当新加入节点或减少节点,需要将新的集群配置表分发到各个节点上,这一行为与其他日志分发并无不同。如果在分发过程中,leader挂掉了,那么可能发送一种情况是:具有旧集群配置表的节点们会选出一个leader,而新集群配置表的节点们也可能选举出一个leader,最终造成一个集群两个leader。
解决办法是每次只变更一个节点。事实证明,每次只变更一个节点不会产生分裂的情况,因为不会出现同时有两个超过半数以上子集群的存在。当添加一个节点,leader把变更日志分发到其他节点,假设leader出现了崩溃,重新选举。这个时候,会有2个结果:
(1)新配置复制到了集群的大多数并提交,如果leader挂掉,新配置范围内至少有一个节点,它是从旧配置变为新配置,它与新节点和旧节点都相互感知,并且它的log index领先于旧节点,它能同时得到新节点和旧节点的选票,所以肯定能在新一轮选举中胜出,新leader肯定使用的是新的配置。
需要注意的是,要确保leader挂掉后以旧节点视角来看必须还有过半节点存活,否则旧节点将认为集群不可用,这种情况一般出现在集群原本只有2个节点,然后新增1个节点。
(2)新配置没有复制到集群的大多数或还未提交,实际上新配置并没有被提交,所有节点用的还是旧配置,旧节点还未感知新节点,所以新leader必然还是从旧节点当中选出,接收到变更日志的节点具有更大log index,新leader会在它们中选出,选出后新leader继续同步变更日志,接着上一轮还没进行完的成员变更过程。
可以参考论文中的图:
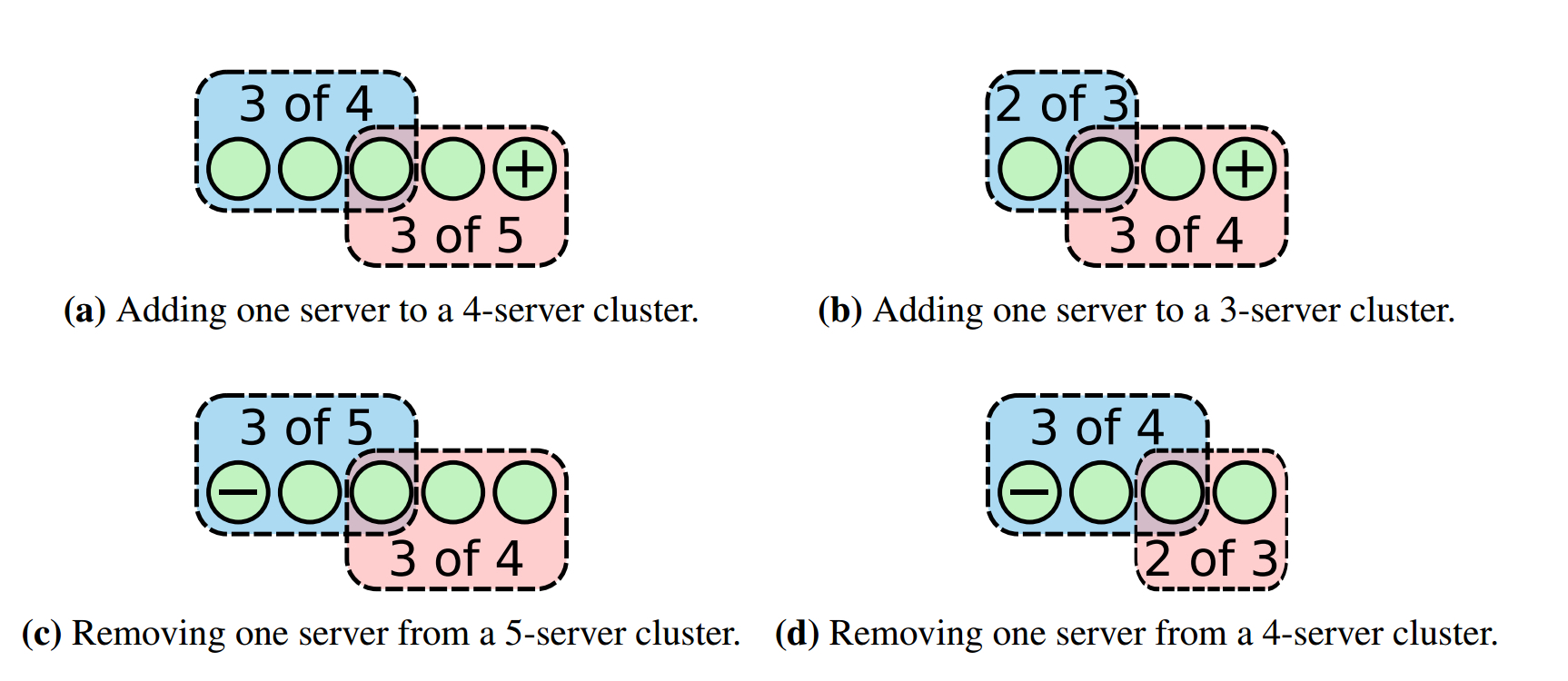
如果同时加入超过一个节点,可能新节点加leader就超过了半数,很可能日志只同步到新节点就提交了,若leader挂掉,则新配置范围和旧配置范围不存在相互感知的节点,新节点知道旧节点,但旧节点不知道新节点。如果新节点数量少于半数,则新节点范围的集群会陷入不可用状态,而旧节点照常选举。如果新节点超过半数,则导致新节点范围自己选举,旧节点范围也自己举行选举,导致脑裂。
加入新节点
当加入新节点时,需要告诉leader,有新节点加入,但新节点不会马上加入集群的运作当中。leader会先向改节点同步数据,分多轮同步,直到新节点的数据追上集群的进度才加入集群。也就是说上面说到的成员变更加入新节点的过程一定是新节点进度追上集群后才发生的。通常,新节点追进度时会被称为learner。
既然日志同步是自动进行的,为什么还要等新节点的进度追上来后才加入集群?因为新节点必须把过往日志都同步才能确认log index更大的新日志。如果不设置learner阶段,若是刚加入一个新节点,就有一个节点挂掉了,而新加入节点的log index没有跟上,它长时间无法确认新日志,相当于同时有两个节点不可用,如果集群当前有4个节点,两个不可用,整个集群就不可用了。
删除节点和网络分区
一个节点被移除后,它自己可能不知道这个情况,它发现没有leader的心跳,自己就会发起选举。如果它的日志不是最新的,它总是无法获得投票,但是又没有leader,所以隔一段时间又再次发起投票,以此类推,老是发起选举会干扰到集群;如果它的日志是最新的,会导致集群节点给它投票,进而可能让一个被移除的节点成为leader。
为了防止被移除的节点成为leader,每个节点在投票之前需要检查自己在一定时间内有没有收到心跳,如果又收到心跳,说明leader还存活,没必要给别人投票。然而因为被移除节点无法知道自己已经被移除,所以还可以发起选举,虽然不会成为leader,但一直持续下去也不好,最好在通知leader移除节点后把该节点对应的进程停掉。其实可以考虑加一种移除消息类型,当节点收到该消息后把自己停掉就好了。
网络分区类似,在节点通信故障后又重新连回集群后,该节点在多次发起选举后term可能变得很大,收到leader的心跳后发现自己的term比leader的更大,就回应一个消息 [src],leader发现对方term比自己大,就把自己变成follower [src],等待一段时间后触发新一轮选举。
解决网络分区term过大的问题的办法是PreVote,即预投票。Candidate先发起一次预投票,若是自己能获得大多数节点的投票就发起一次正式投票,如果不能则不能增加term。
Comments