
文件是磁盘信息的抽象概念,使用户不用了解实际磁盘工作方式等细节,而文件系统则是对文件在磁盘上的存储进行规范,同时为用户访问文件提供接口。这里主要描述文件系统的一些概念,工作原理和实现方法。
分区
磁盘可以划分为多个分区,每个分区可以运行一套独立的文件系统。磁盘的0号扇区,即开头位置,为主引导记录(Master Boot Record,MBR),在计算机启动时用来引导计算机。MBR的结尾有一个分区表,该表给出了每个分区的起始和结束地址。
虽然你的磁盘上可能有多个分区,但计算机必须先找到操作系统所在的分区,即活动分区,而该分区的第一个位置被称为引导块,用于引导计算机去启动该操作系统。其实,不管是不是活动分区,每个分区的第一个位置都默认作为引导块。在计算机被引导时,BIOS读入并执行MBR。MBR做的第一件事是找到活动分区,读入它的引导块(boot block),并执行之。
而分区的第二个位置则是超级块(superblock),在计算机启动时,会把超级块读入内存。超级块中的信息包括:确定文件系统类型用的魔数 (magic number)、文件系统中数据块的数量以及其他重要的管理信息。
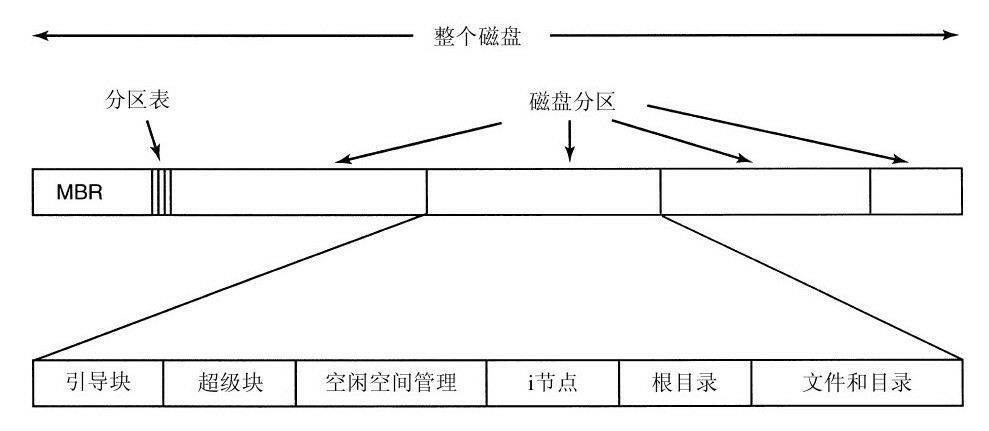
接着是文件系统中空闲块的信息,例如,可以用位图或指针列表的形式给出。后面跟随的是一组i节点,这是一个数据结构数组,每个文件一个,i节点说明了文件的方方面面。接着是根目录,它存放文件系统目录树的根部。最后,磁盘的其他部分存放了其他所有的目录和文件。
i节点
i节点是一个数据结构,其记录着若干个磁盘块的位置。一般,一个文件就是一个i节点。因为磁盘块的大小是不定的,可能是1kb或2kb,而文件的大小可能大于该值,所以文件可能离散存到多个磁盘块中。
i节点的实现可以是多样的。比如把磁盘块存储结构设计为数组,用另一个变量表示其长度。也可以为一个i节点设计固定的磁盘块数量,然后用一个变量指向另一个磁盘块存储结构,来扩展磁盘块数量。
日志结构文件系统
Linux ext2等UNIX文件系统有一些弊端,一个是读写速度慢,每一次写操作都必须马上写入磁盘,而每次磁盘寻道操作都会对后面的操作造成延迟,有时也不能充分使用磁盘带宽,假设一个磁盘的带宽是1M,每次写操作要花10ms,如果你一次只写20kb,意味着写速度只有20kb/10ms。而如果你能缓冲1M的数据量,再一次性写入,这时的速度就是1M/10ms,充分利用了磁盘带宽。
日志结构文件系统(Log-structured File System,LFS),在内存中设立一个缓冲队列,把写操作缓冲到队列中,每隔一段时间,被缓冲在内存中的所有未决的写操作都被存到磁盘中。多个写操作可能组成一个段,一个段可能会包括i节点、目录块、数据块,如果所有的段平均在1MB左右,那么就几乎可以利用磁盘的完整带宽。
LFS会把i节点缓存到磁盘或内存中,称为i节点图。要打开一个文件,则首先需要从i节点图中找到文件的i节点。一旦i节点定位之后就可以找到相应的块的地址。
如果我们删除了一个文件,除了需要更新i节点图,还需要回收段中的i节点。LFS有一个清理线程,该清理线程周期地扫描日志进行磁盘压缩。线程会扫描每一个段的i节点,然后查看当前i节点图,判断该i节点是否有效以及文件块是否仍在使用中,如果没有使用,那么i节点和块就进入内存等待写入到下一个段中,原来的段被标记为空闲,以便可以用它来存放新的数据。
虽然基于日志结构的文件系统是一个很吸引人的想法,但是由于它们和现有的文件系统不相匹配,所以还没有被广泛应用。
日志文件系统
日志结构的基本想法是保存一个用于记录系统下一步将要做什么的日志。这样当系统在完成它们即将完成的任务前崩溃时,重新启动后,可以通过查看日志,获取崩溃前计划完成的任务,并完成它们。这样的文件系统被称为日志文件系统,并已经被实际应用。微软的NTFS文件系统、Linux ext3和ReiserFS文件系统都使用日志。
考虑一个删除文件的操作,可能分三个步骤: 一是在目录中删除文件,二是释放i节点到空闲i节点池,三是将磁盘块归还到空闲磁盘块池。假设系统在步骤一后崩溃,那么文件对应的i节点和磁盘块就无法得到释放,在其他步骤处崩溃也会导致不一致性。
日志文件系统会先把操作写作日志,然后持久化到磁盘,确保存入后才开始执行操作,操作全部成功后,才擦除日志。如果系统崩溃,则检查日志来重新运行未完成的操作。这么做意味着一个操作可能会被执行多次,这要求操作重复执行的结果是一样的,即操作具有幂等性。比如,“把i节点k加入空闲表的末端”就是不幂等的,而“如果k不在空闲表则把k加入”则是幂等的。
虚拟文件系统
事实上,一个操作系统可能用到多种文件系统,比如Linux可能把ext2作为根文件系统,而/home用的是ext3,以及装载一个CD到/mnt下,用的是ISO 9660。这时候需要用一个中间层来统一接口,屏蔽不同文件系统的操作差异,该中间层被称为虚拟文件系统(Virtual File System,VFS)。

VFS提供一个POSIX接口给用户进程调用,一般程序访问的是VFS而不是实际的文件系统。
当系统启动时,装载进来的文件系统必须向VFS注册,注册时需要提供规定的函数列表,比如read, write, close等。当打开一个文件时,则先根据路径,找到它所在的文件系统,然后通过文件系统注册的接口去打开该文件。具体操作时,VFS会创建一个v节点去调用实际文件系统,文件系统会返回文件的i节点信息,并存到v节点中,v节点也会包含该文件系统的函数列表的指针。
v节点创建后,VFS会在文件描述符表中创建一个文件描述符,并把文件描述符存放一个代理数据结构中,该代理数据结构也会包含该v节点,VFS向调用者返回文件描述符。调用者可以用文件描述符作为POSIX接口的传入值,VFS通过文件描述符找到代理数据结构和v节点,进而操作文件。
比如用户调用read操作,传入文件描述符,VFS通过文件描述符找到v节点,从函数表找到对应函数,向函数传入i节点,由实际文件系统通过i节点找到对应的块并返回数据。

联合文件系统
联合文件系统(Union file system, UFS)允许把多个文件系统进行合并成一个对外文件系统。合并过程中会区分层级,一个文件系统就是一层,合并即是把层堆叠起来,对于用户来说,他打开联合文件系统时,看到的是所有层级合并的结果。如果相同路径和文件名的文件同时存在多个层级,那么只有最高层级的文件对用户可见,其他会被隐藏。联合文件系统有一个原则是:低层文件系统永远是只读的(read-only),只有最高层文件系统是可读写的。
当用户需要查找和读取文件时,会从最高层级开始往下查找,查找到后就返回给用户。当用户创建文件时,则只在最高层的文件系统里创建。当用户修改一个文件,会先判断该文件属于哪一层,如果属于最高层,则直接修改即可;否则,需要从低层把该文件复制到最高层,然后再进行修改,这就是所谓的写时复制(Copy On Write)。
当用户删除一个文件时,先判断文件属于哪一层,如果在最高层,直接删除即可。否则,会在最高层创建一个whiteout文件,标记哪个文件被删除,查找文件时就会止步,而实际上该文件并未从低层文件系统中删除。当用户删除一个目录时,会创建opaque目录,标记被删除的目录,工作流程和删除文件类似。重命名文件和目录时,只有文件和目录都在最高层才允许操作,否则返回EXDEV错误。
现在有诸多联合文件系统的实现版本,比如AUFS, OverlayFS等。
网络文件系统
网络文件系统(Network File System, NFS),可以使服务器目录挂载到多个客户端的文件系统上。这个过程对于应用程序来说是透明的,应用程序并不用关心它访问的文件是本地的还是远程的,只需通过VFS的接口访问文件即可。

NFS经过多个版本的迭代,其中第三版的NFS并不支持open和close操作,因为设计者认为对远程文件的读取和写入的操作都要求是幂等的,而且对于客户端来说,read和write只是涉及数据块的传输而已,真正发生open和close操作是在服务器上。而且这样的话,对于服务器来说是无状态的,read操作的偏移量和块字节数的维护都发生在客户端上。第四版的NFS支持open和close操作,即服务器的NFS变为有状态的。
对于NFS的实现原理,上面说过,VFS会对文件维护一个v节点,指向本地文件i节点。而客户端NFS则维护一个r节点,与远程文件的i节点对应。如果文件是一个远程文件,VFS的v节点则会指向其r节点。假设客户端需要读取一个远程文件,内核会先判断这是一个远程目录,然后NFS驱动向远程请求该文件的文件句柄(文件描述符),并为此创建一个r节点,同时v节点指向该r节点。
后续的操作都是通过该文件描述符标识,VFS会通过NFS驱动向远程发出请求,消息包含描述符、偏移量和字节数等。一般默认的读取字节数是8kb。到客户端收到8kb块后,不管用户程序有没有继续请求,都会自动请求下一块,这个特性称为预读(read ahead),以便于需要下一块时可以快速得到。同理,当客户端通过write写数据时,也会积累到8kb才会发送到服务器,除非你手动刷新或关闭文件。
NFS会提供缓存机制,方便对同一个文件进行多次快速读取。但缓存会导致多个客户端同时读写时的数据不一致问题,这时,要么可以通过定时清理缓存来解决,要么通过与服务器比较文件的最后修改时间解决。
Comments