
BERT,完整描述是使用双向编码器的Transformer (Bidirectional Encoder Representations from Transformers), 是Google在2018年发布的一个神经网络模型 [1]。该模型与以往大多数NLP模型不同,它本身便是一个用于迁移训练的模型。
对于迁移训练,在计算机视觉中迁移训练已经是个常态了,一般都是在经过ImageNet数据训练的预训练模型上进行微调。如今,研究人员在处理NLP问题上也希望能够通过预训练来提高模型能力。而BERT的该论文主要阐述如何在BERT模型上进行预训练,然后基于预训练模型,对于不同任务(task)进行微调。
预训练与微调方法
早于BERT,OpenAI GPT提出了在transformer上进行预训练和微调的方法 [2],不过与BERT不同的是,GPT采用的是单向transformer以及使用无监督数据来学习语言模型。BERT采用的方法是基于无监督数据采用有监督方法进行预训练,详细方法后面会讲到。
模型结构
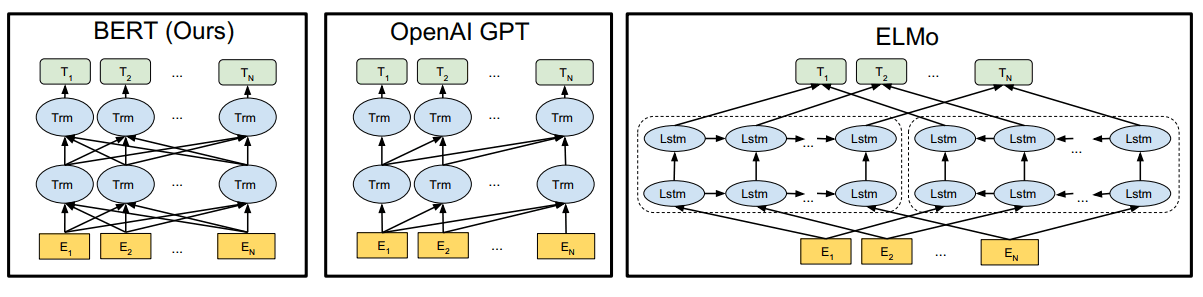
上图是BERT与几个相似模型的对比,只有BERT在所有层级上都加入了左右上下文的信息。
输入表示
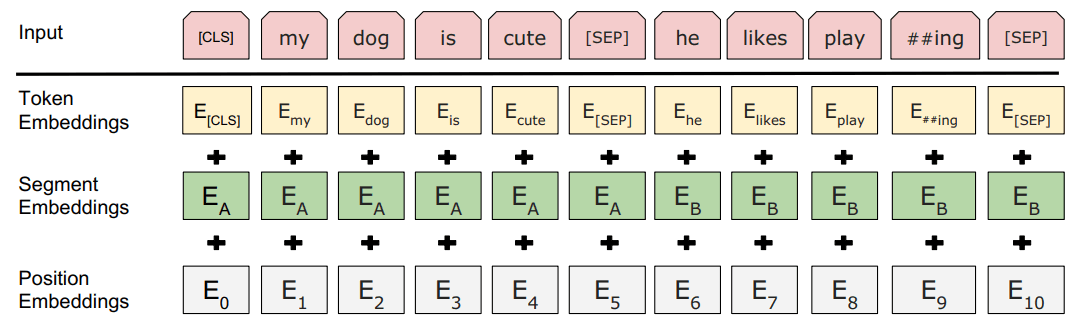
输入向量由三层组合 1. Token Embeddings 即词向量。[CLS] 表示开始标志,[SEP] 用于分割多个句子的标志 2. Segment Embeddings 段落向量。上图中的\(\large E_A, E_B\) 表示两个学习过的句子A和B。为什么这么做后面会讲到。 3. Position Embeddings 位置向量。这里的位置向量不使用余弦函数,而是需要进行训练。
预训练任务
下面会介绍几个用于预训练的任务。
Masked LM
BERT 最重要的特点就是双向,能够同时掌握上下文的信息。但是这里就出现了一个问题,convS2S和transformer都在致力于使用masked去清除“过去”的影响,BERT论文中提到这么做是因为在双向多层结构中词汇会在第二层以后看到“自己”,所以要清除这种干扰。
而为了使得BERT这样的双向结构能够进行良好的训练,作者提出了使用Masked LM方法 [3],该方法就是对于输入的句子,随机遮住(mask)掉一些词汇(token),然后让模型去预测这个词汇。明显,token被mask掉以后就不会出现自己干扰自己的情况。mask的时候使用[MASK]标记即可。
但是这么做会产生一个弊端,这个[MASK]标记在微调(fine-tuning)中是不会出现的,为了减轻该影响,作者提供了方案: 1. 80% 的情况下,替换为[MASK],比如 my dog is hairy -> my dog is [MASK] 2. 10% 的情况下,替换为随机词,比如 my dog is hairy -> my dog is apple 3. 10% 的情况下,不替换
下一句预测
就是将句子A和句子B通过[SEP]拼接起来,问你句子B是不是句子A的下一句。
举两个例子:
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
微调
提取最后一层中 [CLS]标记所在隐藏状态 \(\large C \in \mathbb{R}^H\),以及你自己加上去的权重 \(\large W \in \mathbb{R}^{K \times H}\),\(\large K\) 即你的分类数。通过Softmax进行预测:
\[ \large P = softmax(CW^T) \]
对于超参数的调节,视不同任务而定,作者建议的参数有:
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 3, 4
为了方便理解,作者提供对于不同任务的微调的图示:
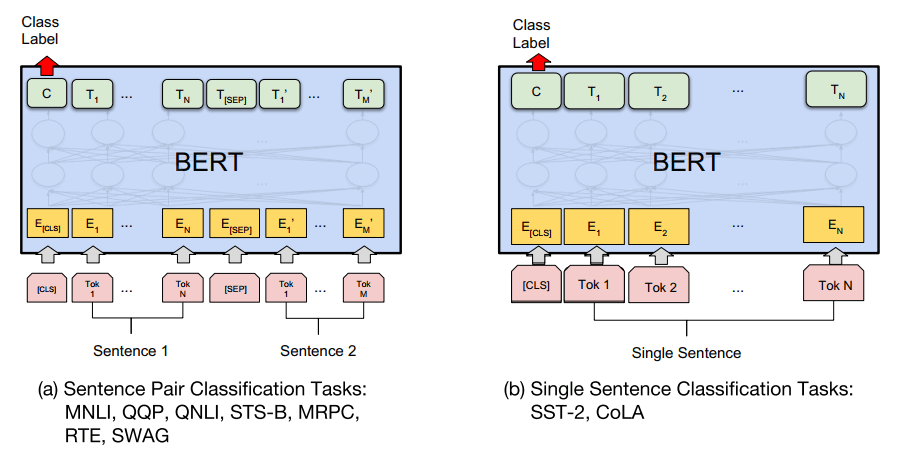
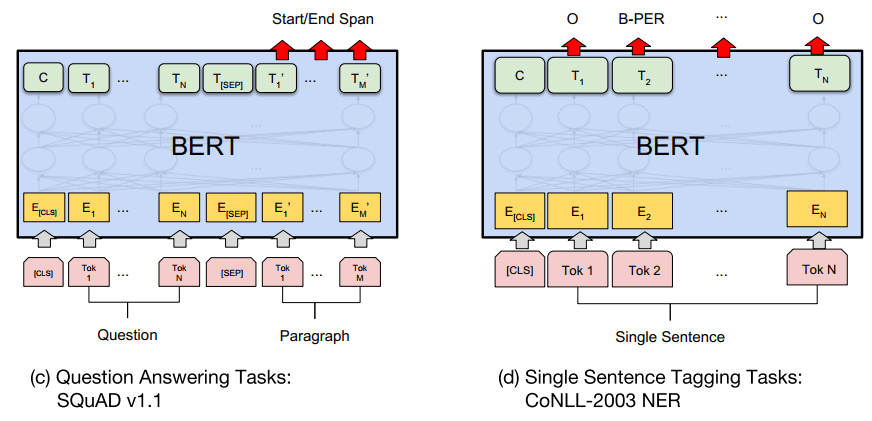
实验结果
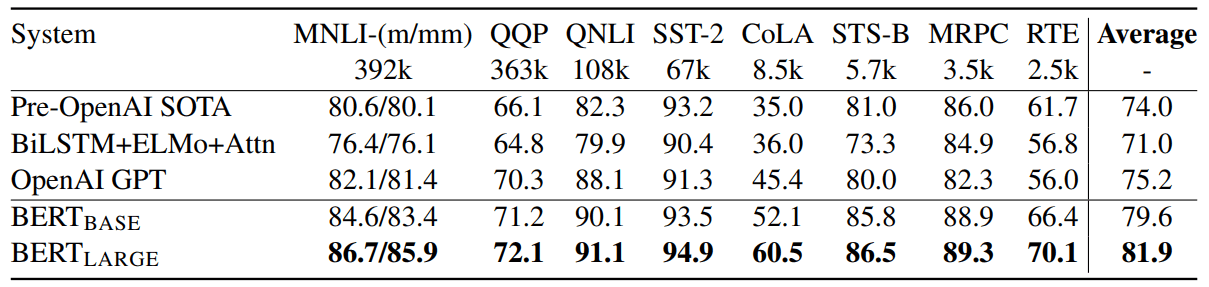
从上图可以看出,BERT在各项任务上的表现基本是毫无敌手。(以上指标均为GLUE [4])
总结
BERT的实验结果表明预训练模型的优越性,尽管BERT本身有些瑕疵,但论文本身阐述了诸多预训练的方法和理论,并且表现出强劲的实力,可以说是NLP史上的一座重要的里程碑了。
尽管BERT能够适用于诸多任务,但也有一些任务无法胜任,比如机器翻译……
参考文献
- [1] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. 2018
- [2] Improving Language Understandingby Generative Pre-Training. 2018
- [3] “Cloze Procedure”: A New Tool for Measuring Readability. 1953
- [4] GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. 2018
Comments